WikiBtsSio
Bts1B2526S46Me
PagePrincipale ::
DerniersChangements :: DerniersCommentaires :: ParametresUtilisateur ::
Vous êtes 216.73.217.95
Lundi 10 novembre 2025
Le mardi 11 novembre est férié.
Jeudi 13 novembre 2025
10 heures 30
Cours B1.
Pas de quiz aujourd'hui.
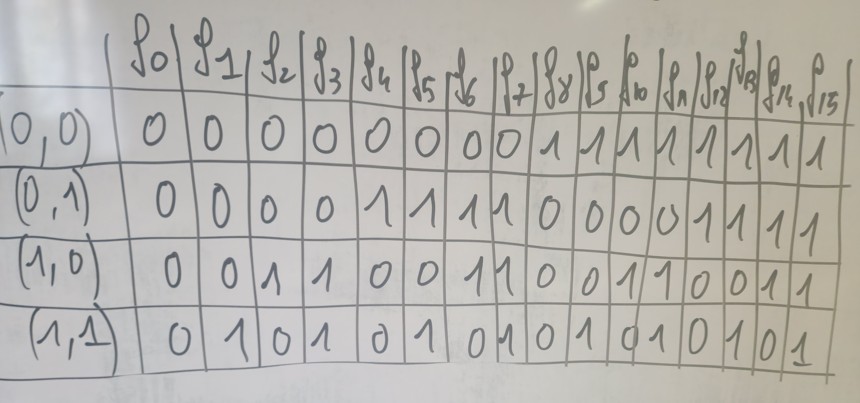
Retour sur les fonctions binaires :
Le RAID
En informatique, le mot RAID désigne les techniques permettant de répartir des données sur plusieurs disques durs afin d'améliorer soit la tolérance aux pannes, soit la sécurité, soit les performances de l'ensemble, ou une répartition de tout cela.
L'acronyme RAID a été défini en 1987 par l'Université de Berkeley, dans un article nommé A Case for Redundant Arrays of Inexpensive Disks (RAID), soit « chaîne redondante de disques peu onéreux ». Aujourd'hui, le mot est Schéma de principe d'une grappe de disques en RAID 5 devenu l'acronyme de Redundant Array of Independent (or inexpensive) Disks, ce qui signifie « chaîne redondante de disques indépendants ». Le coût au mégaoctet des disques durs ayant diminué d'un facteur 1 300 000 en 29 ans, aujourd'hui le RAID est choisi pour d'autres raisons que le coût de l'espace de stockage



Le RAID 0 : fragmentation des données sur plusieurs supports
Structure RAID 0
Les blocs de données sont alternativement stockés sur les supports disponibles. Cela confère une plus grande rapidité au détriment de la fiabilité de l'ensemble. Les blocs de données peuvent être écrits ou lus en parallèle, à la vitesse maximum du périphérique le plus lent. La panne d'un seul des volumes entraine une perte de la totalité des données.
La capacité totale est un multiple du plus petit support utilisé : on utilise donc des supports de même capacité.
Le RAID 0 est parfois appelé « entrelacement de disques » ou de « volume agrégé par bandes » (striping en anglais).
Il est utilisé dans les cas où la perte des données n'est pas un problème, par exemple :
Le RAID 1 consiste en l'utilisation de n disques redondants (avec n ≥ 2 ), chaque disque de la grappe contenant à tout moment exactement les mêmes données, d'où l'utilisation du mot « miroir » (mirroring en anglais).
Le RAID 5 : volume agrégé par bandes à parité répartie
Structure RAID 5
Le RAID 5 combine la méthode du volume agrégé par bandes (striping) à une parité répartie. Il s'agit là d'un ensemble à redondance N + 1. La parité, qui est incluse avec chaque écriture, se retrouve répartie circulairement sur les différents disques. Chaque bande est donc constituée de N blocs de données et d'un bloc de parité. Ainsi, en cas de défaillance de l'un des disques de la grappe, pour chaque bande il manquera soit un bloc de données soit le bloc de parité. Si c'est le bloc de parité, ce n'est pas grave, car aucune donnée ne manque. Si c'est un bloc de données, on peut calculer son contenu à partir des N − 1 autres blocs de données et du bloc de parité. L'intégrité des données de chaque bande est préservée. Donc non seulement la grappe est toujours en état de fonctionner, mais il est de plus possible de reconstruire le disque une fois échangé à partir des données et des informations de parité contenues sur les autres disques.
On voit donc que le RAID 5 ne supporte la perte que d'un seul disque à la fois, ce qui devient un problème depuis que les disques qui composent une grappe sont de plus en plus gros (1 To et plus), car le temps de reconstruction de la parité en cas de disque défaillant est allongé (ce qui augmente la probabilité de survenue d'une nouvelle défaillance car les autres disques durs sont sollicités de façon intensive durant la reconstruction). Ainsi, le temps de reconstruction est long, et plus les disques sont volumineux, plus la durée de reconstruction est longue. Pour limiter le risque, il est courant d'ajouter un disque de rechange (spare), dédié au remplacement immédiat d'un éventuel disque défaillant : en régime normal celui-ci est inutilisé ; en cas de panne d'un disque, il prendra automatiquement la place du disque défaillant. Cela nécessite une phase communément appelée recalcul de parité, consistant à recréer sur le nouveau disque le bloc manquant (données ou parité) pour chaque bande. Pendant le processus de recalcul de parité, le volume RAID reste disponible normalement, le système se trouve juste un peu ralenti.
Je vous présente uniquement les sauvegardes incrémentielles (appelées aussi incrémentales) et différentielles toujours liées à une sauvegarde complète.
L'incrémentielle se base sur la sauvegarde précédente, la différentielle se base sur sa sauvegarde complète. L'incrémentielle nécessite moins d'espace de stockage, mais demande un temps de restauration plus long.
La différentielle nécessite plus d'espace de stockage, mais demande un temps de restauration plus court.
La sauvegarde incrémentielle.
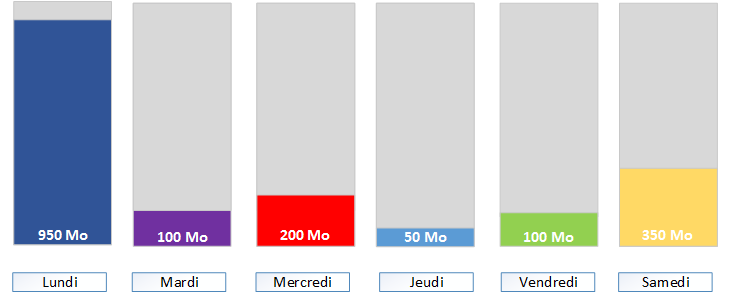
Sur cet exemple je suis partie d'une sauvegarde sur une semaine.
La sauvegarde différentielle.
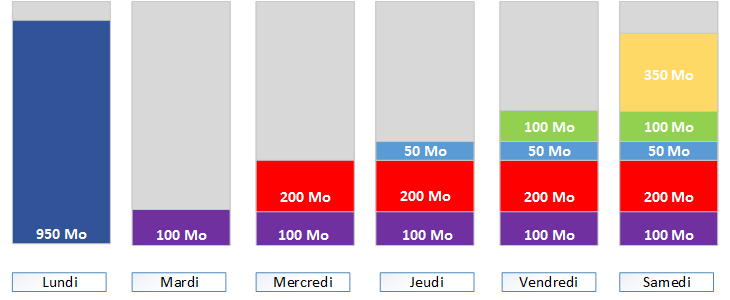
Représentation d'une sauvegarde différentielle sur une semaine
Sources :
L'ensemble des fonctions binaires à deux variables.
Python calculer le temps d'exécution :
Importer le module time -->
TP B1
13 heures 30 - groupe 1
15 heures 30 - groupe 2
Utilisation de VirtualBox.
Commande hostname : sudo nano /etc/hostname et sudo nano /etc/hosts (adresse IP et nom).
Afficher vos adresse IP et noter le nom de vos cartes réseau : ip a
Nom de vos cartes eth0 eth1 ou enps3 enps8
Pour activer vos deux cartes sudo ip link set dev ethx up (ou enpsx) avec x un chiffre !
Lister le fichier du réseau existant dans le répertoire ls /etc/netplan
Editer le fichier trouvé sudo nano /etc/netplan00-installer-config.yaml (ou 99_config.yaml, ...)
sudo netplan apply
sudo apt full-upgrade
sudo poweroff
Vendredi 14 novembre 2025
10 heures 30
TP B1 - groupe 1
Le mardi 11 novembre est férié.
Jeudi 13 novembre 2025
10 heures 30
Cours B1.
Pas de quiz aujourd'hui.
Retour sur les fonctions binaires :
Le RAID
En informatique, le mot RAID désigne les techniques permettant de répartir des données sur plusieurs disques durs afin d'améliorer soit la tolérance aux pannes, soit la sécurité, soit les performances de l'ensemble, ou une répartition de tout cela.
L'acronyme RAID a été défini en 1987 par l'Université de Berkeley, dans un article nommé A Case for Redundant Arrays of Inexpensive Disks (RAID), soit « chaîne redondante de disques peu onéreux ». Aujourd'hui, le mot est Schéma de principe d'une grappe de disques en RAID 5 devenu l'acronyme de Redundant Array of Independent (or inexpensive) Disks, ce qui signifie « chaîne redondante de disques indépendants ». Le coût au mégaoctet des disques durs ayant diminué d'un facteur 1 300 000 en 29 ans, aujourd'hui le RAID est choisi pour d'autres raisons que le coût de l'espace de stockage
Le RAID 0 : fragmentation des données sur plusieurs supports
Structure RAID 0
Les blocs de données sont alternativement stockés sur les supports disponibles. Cela confère une plus grande rapidité au détriment de la fiabilité de l'ensemble. Les blocs de données peuvent être écrits ou lus en parallèle, à la vitesse maximum du périphérique le plus lent. La panne d'un seul des volumes entraine une perte de la totalité des données.
La capacité totale est un multiple du plus petit support utilisé : on utilise donc des supports de même capacité.
Le RAID 0 est parfois appelé « entrelacement de disques » ou de « volume agrégé par bandes » (striping en anglais).
Il est utilisé dans les cas où la perte des données n'est pas un problème, par exemple :
- données temporaires (résultats de calculs intermédiaires, etc.)
- données stockées ailleurs (sauvegarde, système distant)
- mise en cache pour accès rapide de données pourtant locales (fichiers vidéo à streamer, fichiers de jeux vidéo permettant leur chargement plus rapide, etc.).
Le RAID 1 consiste en l'utilisation de n disques redondants (avec n ≥ 2 ), chaque disque de la grappe contenant à tout moment exactement les mêmes données, d'où l'utilisation du mot « miroir » (mirroring en anglais).
Le RAID 5 : volume agrégé par bandes à parité répartie
Structure RAID 5
Le RAID 5 combine la méthode du volume agrégé par bandes (striping) à une parité répartie. Il s'agit là d'un ensemble à redondance N + 1. La parité, qui est incluse avec chaque écriture, se retrouve répartie circulairement sur les différents disques. Chaque bande est donc constituée de N blocs de données et d'un bloc de parité. Ainsi, en cas de défaillance de l'un des disques de la grappe, pour chaque bande il manquera soit un bloc de données soit le bloc de parité. Si c'est le bloc de parité, ce n'est pas grave, car aucune donnée ne manque. Si c'est un bloc de données, on peut calculer son contenu à partir des N − 1 autres blocs de données et du bloc de parité. L'intégrité des données de chaque bande est préservée. Donc non seulement la grappe est toujours en état de fonctionner, mais il est de plus possible de reconstruire le disque une fois échangé à partir des données et des informations de parité contenues sur les autres disques.
On voit donc que le RAID 5 ne supporte la perte que d'un seul disque à la fois, ce qui devient un problème depuis que les disques qui composent une grappe sont de plus en plus gros (1 To et plus), car le temps de reconstruction de la parité en cas de disque défaillant est allongé (ce qui augmente la probabilité de survenue d'une nouvelle défaillance car les autres disques durs sont sollicités de façon intensive durant la reconstruction). Ainsi, le temps de reconstruction est long, et plus les disques sont volumineux, plus la durée de reconstruction est longue. Pour limiter le risque, il est courant d'ajouter un disque de rechange (spare), dédié au remplacement immédiat d'un éventuel disque défaillant : en régime normal celui-ci est inutilisé ; en cas de panne d'un disque, il prendra automatiquement la place du disque défaillant. Cela nécessite une phase communément appelée recalcul de parité, consistant à recréer sur le nouveau disque le bloc manquant (données ou parité) pour chaque bande. Pendant le processus de recalcul de parité, le volume RAID reste disponible normalement, le système se trouve juste un peu ralenti.
Je vous présente uniquement les sauvegardes incrémentielles (appelées aussi incrémentales) et différentielles toujours liées à une sauvegarde complète.
L'incrémentielle se base sur la sauvegarde précédente, la différentielle se base sur sa sauvegarde complète. L'incrémentielle nécessite moins d'espace de stockage, mais demande un temps de restauration plus long.
La différentielle nécessite plus d'espace de stockage, mais demande un temps de restauration plus court.
La sauvegarde incrémentielle.
Sur cet exemple je suis partie d'une sauvegarde sur une semaine.
- Pour commencer, il va falloir réaliser en premier lieu une sauvegarde complète ici le lundi.
- Ensuite, l'incrémentielle du mardi va se baser sur la précédente qui sera cette fois la complète en sauvegardant uniquement les nouveaux fichiers créés ou modifiés entre-temps.
- Mercredi, l'incrémentielle va se baser sur la précédente qui sera cette fois le mardi en sauvegardant uniquement les nouveaux fichiers créés ou modifiés entre-temps.
- Et ainsi de suite jusqu'à la prochaine sauvegarde complète.
- Si on souhaite récupérer l'ensemble de la sauvegarde de la semaine, il faudra restaurer tous les éléments du lundi au samedi ce qui prendra un certain temps, mais cela reste la méthode qui consomme le moins d'espace avec un total de 1750 Mo.
La sauvegarde différentielle.
Représentation d'une sauvegarde différentielle sur une semaine
- Le lundi, on démarre avec une sauvegarde complète. Et c'est à partir de cette sauvegarde que les différentielles se baseront chaque jour.
- Mardi la différentielle va sauvegarder uniquement les nouveaux fichiers créés ou modifiés entre-temps d'après la complète. Soit n.
- Mercredi la différentielle va sauvegarder uniquement les nouveaux fichiers créés ou modifiés entre-temps d'après la complète. Soit n+1.
- Et ainsi de suite jusqu'à la prochaine sauvegarde complète.
- On constate en effet que la sauvegarde du jeudi contient en plus les données du mardi et du mercredi. Étant donné que les différentielles se basent sur la complète et non pas les précédentes, elles ajoutent tous les fichiers ajoutés ou modifiés depuis le lundi.
- Si on souhaite récupérer l'ensemble de la sauvegarde de la semaine, il faudra restaurer simplement le lundi et le samedi qui correspondent à l'ensemble de la semaine. La restauration prendra donc moins de temps, mais c'est la méthode qui consomme le plus d'espace avec un total de 2950 Mo.
Sources :
- Source (PDF).
- Source wikipedia.
- sauvegarde incrémentielle et différentielle
- RAID 5 : volume agrégé par bandes à parité répartie sous Windows Server 2022 (vidéo avec démo).
L'ensemble des fonctions binaires à deux variables.
Python calculer le temps d'exécution :
Importer le module time -->
- import time
- start_time = time.time()
- end_time = time.time()
- elapsed_time = end_time - start_time
- print(f"Temps écoulé : {elapsed_time} secondes")
TP B1
13 heures 30 - groupe 1
15 heures 30 - groupe 2
Utilisation de VirtualBox.
Commande hostname : sudo nano /etc/hostname et sudo nano /etc/hosts (adresse IP et nom).
Afficher vos adresse IP et noter le nom de vos cartes réseau : ip a
Nom de vos cartes eth0 eth1 ou enps3 enps8
Pour activer vos deux cartes sudo ip link set dev ethx up (ou enpsx) avec x un chiffre !
Lister le fichier du réseau existant dans le répertoire ls /etc/netplan
Editer le fichier trouvé sudo nano /etc/netplan00-installer-config.yaml (ou 99_config.yaml, ...)
sudo netplan apply
sudo apt full-upgrade
sudo poweroff
Vendredi 14 novembre 2025
10 heures 30
TP B1 - groupe 1
Il n'y a pas de commentaire sur cette page.
[Afficher commentaires/formulaire]